The Neurotech Ai
0%
Loading...
Building effective computer vision models requires large volumes of high-quality training data to accurately detect, identify, classify, and track objects. We prepare and optimize datasets that enable machines to see, analyze, and understand the visual world.
We also power automated monitoring and surveillance systems by processing and interpreting images, videos, and other visual inputs—enabling intelligent insights and timely decision-making.
COCO is a large-scale dataset comprising over 330K images and 2.5 million annotated object instances. Its rich diversity of real-world scenes makes it ideal for training and benchmarking advanced computer vision models.
PASCAL VOC is widely used for image classification and object recognition. It also serves as a reliable benchmark for object detection, supporting the development of robust real-world AI applications.
Primarily developed for image classification, ImageNet is extensively used for pre-training and fine-tuning models, helping improve accuracy across various computer vision tasks.
Open Images is a comprehensive dataset with over 9 million images and 600K+ object annotations. Its large scale and diversity make it a preferred choice for building high-performance object detection systems.

High-quality image labeling to train, validate, and optimize machine learning models with precision.
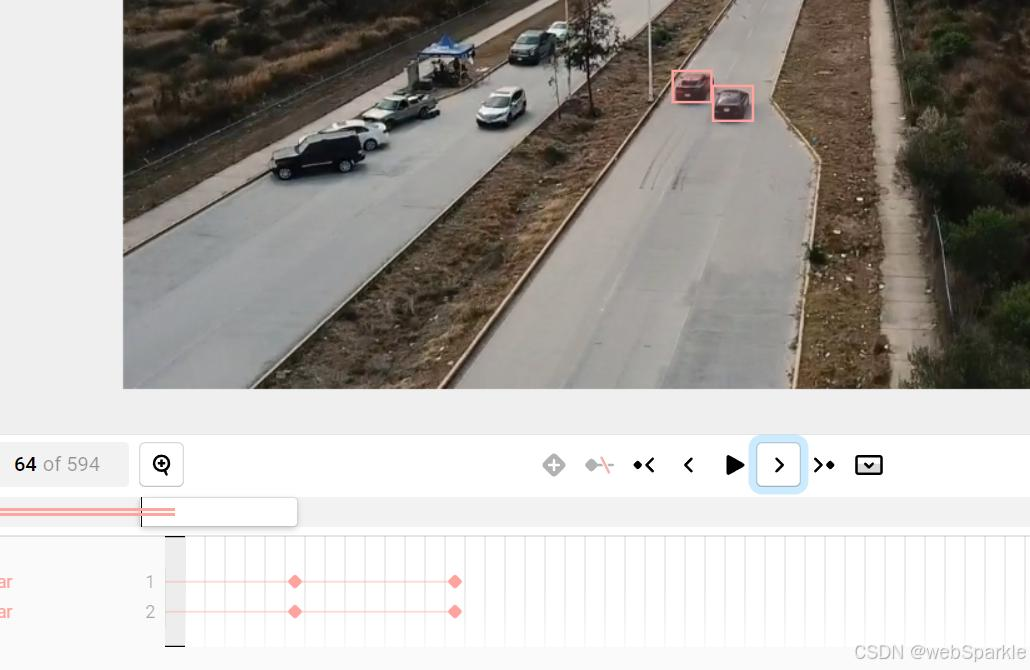
Accurate frame-by-frame video labeling to power reliable and scalable AI model development.
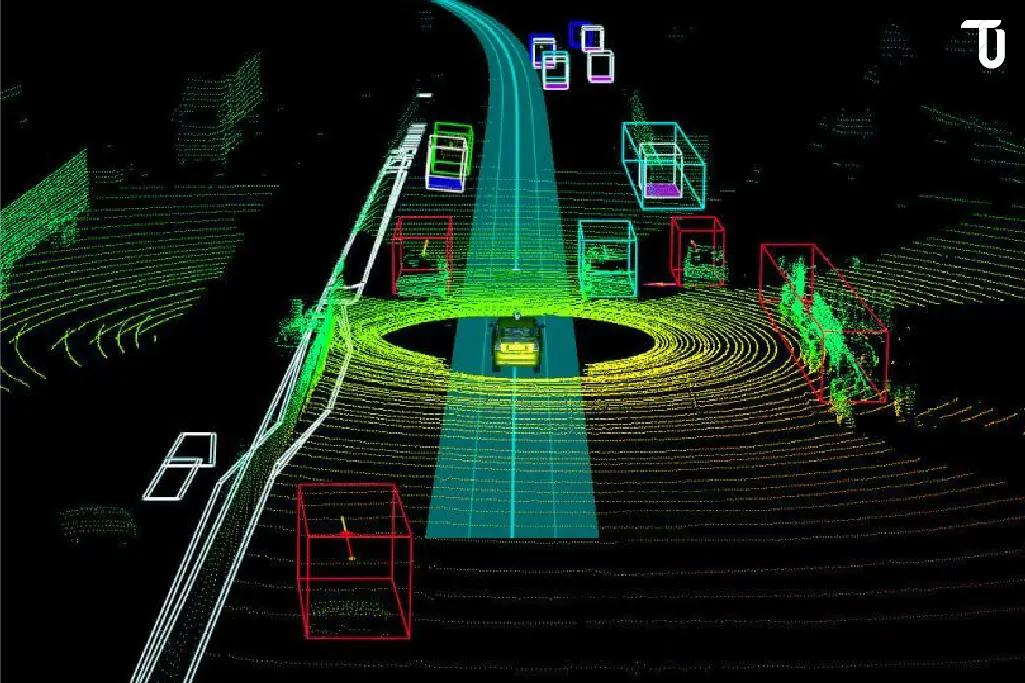
Precise 3D data annotation enabling advanced AI applications like autonomous driving and spatial intelligence

Faster, smarter annotation with semi-automated workflows that boost efficiency and reduce manual effort.
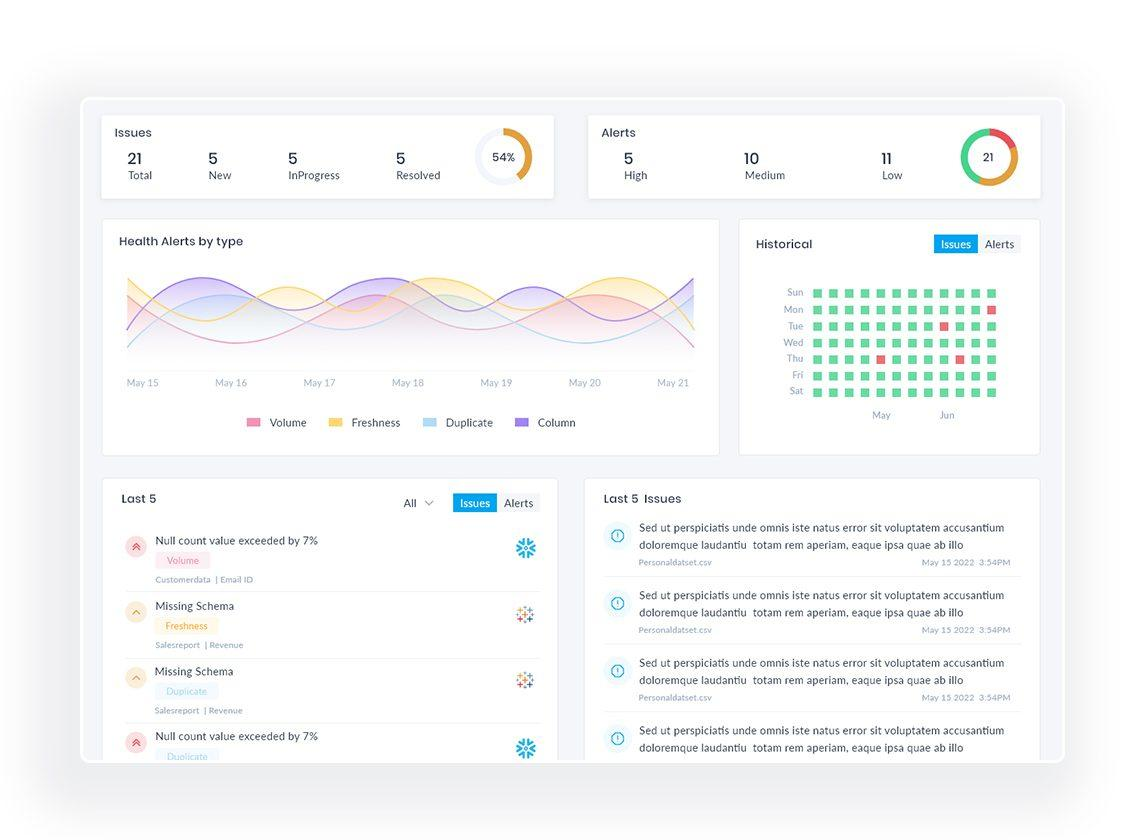
Comprehensive validation to detect errors, refine datasets, and ensure peak model performance.

Seamless, real-time annotation pipelines with optimized task distribution for faster project execution.